
Auditory Masking: Knowing What You Don’t Hear
After the technical topics of the recent weeks, it’s time to talk about human hearing again. Let’s dip our toes into auditory masking!
Ever noticed how some tracks sound totally different in the mix compared to solo? Other tracks seem to be completely buried and you need to make them irrationally loud for them to stick through. The reason behind that is very likely auditory masking. But what does that mean exactly? Let’s see.
Most topics around the capabilities of human hearing are about what you can hear and what you can’t hear. Having good knowledge about that is essential for example to determine sensible requirements to our digital recording equipment. And of course it’ll give you the ability to employ some neat tricks.
The most basic techniques of audiology aim to measure static limitations of hearing, such as the softest and loudest sounds, or the highest and lowest frequencies we can perceive. But the ears are much more complicated than just that. In more complex signals and mixtures, sounds that would be clearly audible alone become inaudible in the presence of another signal. This is essentially what auditory masking is about.
There are several different types of masking, but today we’ll focus on frequency-based effects with static sounds. Another class of masking effects are temporal masking effects which are related to the dynamic changing of sounds in time. That’ll be a whole different topic.
How Does Auditory Masking Work?
As you know already, the human hearing splits up sound into different frequency bands and then analyzes this data. Simply put, it’s pretty much looking at a spectrum analyzer all the time.
It’s the basilar membrane that actually does the job of frequency-splitting by resonating with different frequencies more strongly at different locations along the membrane. But of course the localization of these vibrations isn’t infinitely sharp. A single frequency excites the membrane over a broader range of locations.
And since the nerve responses to membrane vibrations follow a logarithmic law (simply put, it’s measuring Decibels rather than Volts), adding a softer sound to this vibration doesn’t “move the needle” very much, even if the second sound is at a different frequency.
Can We Anticipate It Somehow?
The question is, can we make a quick ballpark estimate to anticipate what frequency regions are affected by strong sound components? Of course we can. Audiologists spent decades measuring these effects with quite some precision. But for us, it’s enough to have a rough overview about what happens.
The best way to think about it is that a narrowband sound (usually noise filtered with a very steep bandpass filter) at a certain frequency raises the threshold of hearing for frequencies, and that’s what audiologists measure. They play back a sound with a certain level and frequency (the masker) and measure how loud a second sound at another frequency must be to be perceived.
Here’s a rough qualitative illustration of how the hearing threshold changes in the presence of narrowband noise at different levels around 1 kHz. The blue line depicts the hearing threshold in quiet.
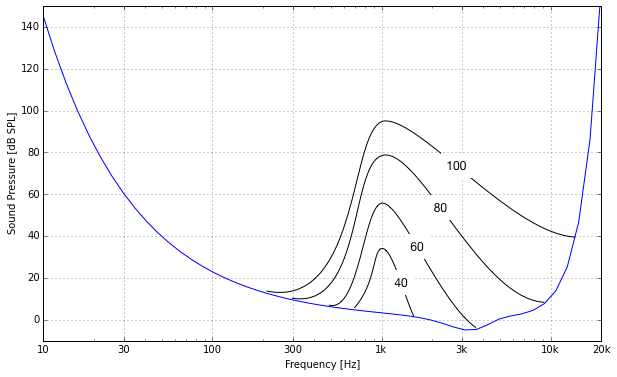
Quite obviously, the “raised” hearing threshold due to the masker signal is highest around the masker frequency. If the second sound in the same frequency range is more than 3dB softer than the masker, it isn’t heard.
The threshold decreases with a very steep slope of around 100dB/oct towards lower frequencies. Thus, the masking effect is nearly inexistent below the masker frequency. What a relief!
However, the interesting stuff happens at frequencies higher than the masker. Not only is the slope there more shallow, but its steepness also varies with masker level. For example for an 80 dB SPL masker, the slope extends up to nearly 10 kHz. This means that the masking is effective more than 3 octaves upwards from the masker frequency, which is quite a lot. For softer sounds, the slope becomes steeper, for louder sounds even shallower.
How To Use Auditory Masking For Good Or Evil
With great knowledge comes great power. And with great power comes great responsibility. Or something like that. So what can we make of knowing what we know about auditory masking?
The most prominent technical use is of course lossy compression algorithms like MP3 or AAC. One of the main strategies of these algorithms is to perform a time-frequency segmentation similar to that of the human ear, apply a psychoacoustic model to estimate masking effects and remove any information that falls below the masked hearing threshold. There are basically two ways to do this.
The first approach is to use the “predicted” hearing threshold to just throw away all the frequencies that are lower in level. Simple thing.
Going a step further you can also look at the soundbites that are above the hearing threshold, but encode them at a lower bitrate and thus increasing quantization noise at that frequency. Ideally, you would permanently adjust the bitrate in a frequency-dependent and dynamic manner so the resulting quantization noise is right below the masked hearing threshold at all frequencies.
If you go too far, you’ll get nasty audible artifacts in exchange for less disk space or streaming bandwidth. This tradeoff is quite freely scalable by adjusting the compression bandwidth.
But understanding auditory masking also helps us figure out where the problems I mentioned in the introduction come from. Since masking extends mostly towards higher frequencies, it is perfectly clear why it’s so important to have a clean and tidy mid range. The often strong fundamentals can easily mud up multiple octaves above them. Be also on the lookout for strong resonances. Not only do they add a ringing, tonal character, but they also mask tones in their vicinity.
But taking masking effects into account is not only a matter of sensible equalization, it’s also a matter of arrangement. If you have problems with clarity in your music, try to listen explicitly which instruments compete with each other. Especially focus on notes within an octave or two above loud and strongly resonant instruments.
Of course you can’t get rid of masking altogether, and you shouldn’t try to anyway. But be aware that different sounds in a mix not only compete in their own respective frequency ranges, but especially in frequency ranges where some of these signals don’t have any content at all.